
Why I am skeptical about the AGI hype
And some observations how AI is best used

With the AI boom in full swing with the possibility of AGI around the corner, I kept throwing more and more stocks onto the ‘too hard’ pile in the past couple of months because future profitability seems hard to judge.
So I thought I would probe the AI hype with something I am somewhat familiar with (and getting more familiar with): writing code. What I noticed is a large disparity between AI hype tech bros, and the views of actual experienced programmers who have to actually make this work in practice instead of just talking about it on podcasts and Twitter. Some interesting comments here, here, here and here. Hackernews also has a lot of interesting discussions.
It is actually surprisingly difficult to find an experienced dev with a positive opinion on vibe coding (where most of the code is generated by AI), other than toy projects and maybe some boilerplate. AI is still mostly a powerful auto complete and summarization tool. My conclusion so far is that we aren’t close to AGI, but instead moving towards a future of specialized idiot savants.
My observations can be summarized as:
Most time spent by programmers on production code is not actually writing the code, but communicating with co-workers, trying to understand, debug and refactor code. Vibe coding potentially greatly increases the amount of time spent doing those activities.
Vibe coding” can speed up feature delivery, but in complex codebases it often spawns unmaintainable, brittle code. Where it may appear productivity gains are made, but debugging and refactoring will take much longer. Junior developers’ productivity appears to go up in the short term, but is more than compensated for by extra time spent by senior devs reviewing AI slop and cleaning up the mess, causing their KPIs to take a hit. Which predictably breeds resentment.
This is a problem with open source code bases as well. A small number of experienced maintainers getting overwhelmed by AI slop PRs.
LLMs often do not tell you when you take a bad approach beyond basic and well documented excercises. It will gladly send you even further down a dead end. If you ask an experienced engineer for assistance they might say “I see what you are trying to do here, but doing y instead of x would be a much better cleaner approach”. The LLM will instead happily give you a thousand terrible ways towards x approach.
Code deflation is still real, especially for more isolated portions of a code base. And things like UIs. Prototyping can also be done much more rapidly.
Management tends to get over excited about prototypes, not realizing that like 80% of the work is actually getting those prototypes to work consistently and securely.
Context size of current LLMs is still way too small. It remains to be seen how well vibe coding works if this increases an order of magnitude.
LLMs can remove the ladder for more inexperienced employees to get better and climb up through practice. As a lot of low level tasks normally done by junior employees will likely be much more automated by AI. I think this will be a problem in a lot of other areas of expertise as well.
Current state of AI fairly powerful if:
Checking the answer is far quicker than coming up with said answer. I have found AI useful while learning maths. As you can check each simple step fairly quickly, coming up with those steps is far more difficult.
Amount of data it is trained on really matters. For example when asking about very well documented historical facts or basic mathematics it will be fairly accurate. Ask it to write Tetris in Python it will likely work well. Ask it about some obscure historical event or to write niche complex business logic in a more unknown language and hallucinations go up exponentially.
This is a strong indication these models are bad at reasoning, but great at extracting human reasoning from large amounts of data. So act accordingly.
It has the amazing ability to remove bottlenecks when learning something new. Normally I might get stuck on a problem and I would have to google for an explanation or ask someone. Sometimes resulting in a significant productivity drop for an hour or two where I might give up altogether for the day. Now I get instant answers that are pretty amazing (as long as the material is basic enough). It really feels like I can speedrun learning new things now.
Searching answers in a large document where a regular key work search does not yield required results.
Detailed structured micro prompts > vague macro prompts. Although manually adding in all the constraints can take longer than actually doing it yourself.
Works much better when wielded by very experienced knowledgeable people. Has potential to do a lot of hard to detect subtle damage if wielded by inexperienced people.
Probably more powerful in languages that have stricter compilers and enough training data like Rust and Scala? The main weakness now is lack of intelligent constraints, which both these languages naturally provide through the compiler.
LLM’s don’t think
Is a phrase I have heard quite a bit. The problem here is that you can get 10 smart people in a room each with a different idea of what ‘think’ means. This is my biggest pet peeve in general with philosophical arguments.
I would define ‘think’ as having at least 2 components, statistically blending and stringing words and pixels together and fundamental reasoning. LLMs are superhuman at the first but I am not so sure they are all that great at the second. Take for example this really simple puzzle, it completely fails to solve it after thinking for more than 7 minutes (used the regular o3 model a week or so ago):
LLMs learn by endlessly tweaking billions of numbers so they get better at guessing the next token. After training, they reply by using those learned patterns to pick the word/pixel combinations that are most likely to follow. It does not really do bottom up reasoning by the looks of it.
But -you might counter- there are plenty of logic problems that o3 does answer correctly, like this one:
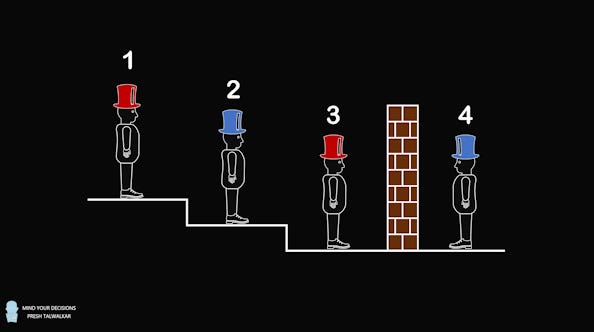
(4 friends have been wrongly imprisoned. Friend 1 can see which color hats friend 2 and 3 have. Friend 2 can only see friend 3. If one of them is able to correctly guess their own hat's color, they will all be set free.
The answer is: Friend 2 can figure out by Friend 1’s silence that Friend 1 sees two different color hats (if Friend 2 and 3 had the same color then by elimination Friend 1 would be able to guess his own hat). Since Friend 2 sees that Friend 3 has a red hat, he can reason his hat has to be blue.)
The question is, when it appears to solve a logic puzzle like this one, is it actually able to come up with a solution through fundamental reasoning or is it summarizing explanations and solutions from countless human written training samples? As this is a fairly common logic problem that readily appears in its training data in various forms. Just because it gives a neat explanation does not mean it is actually able to reason itself to that explanation correctly if the puzzle does not appear in some form in the training data.
In a way it works the same in my head. First time I had to solve it, I had to think it through step by step and figure out which mental models to use. Now I can just quickly generate the solution from memory. First mode resembles fundamental reasoning, second mode resembles an LLM.
So far to make these models better the solution has been to increase size (training data, compute, larger chain of thought, context etc). By doing this it seems it will just get better at repeating and summarizing what we already know and at times intelligently combine pieces of data that have not yet been intelligently combined. Usually guided by a human with good taste.
But I ask, who is smarter:
Someone who can very quickly process large quantities of math books and websites and spit back answers and explanations with high accuracy. But is downright terrible at discovering new math.
Or someone who only studies a handful of math books slowly and discovers vast amounts of new mathematics after doing so?
Basically an idiot savant vs someone like Ramanujan who famously learned most of his math skills from a handful of books. The idiot savant knows more, Ramanujan knows (or knew) less, even about mathematics but discovers more and actually moves mathematics forward. Don’t get me wrong, the first one is incredibly useful, but it is not the imminent Singularity that all the Silicon Valley thinkbois are getting so hyped up about.
What will really be ground breaking is an AI that is fed only maths up until, say, Newton and then can discover calculus and rapidly sprint past Euler. Passing more and more exams (while impressive) is in my opinion not the hallmark of an AGI. Right now 99% of knowledge of an LLM is made by humans. But a true AGI would need only only a small % to get to the same level as an LLM that is trained on every available piece of quality data.
To come back to programming, the main problem with training an LLM on a large amount of publicly available code is that most of that code is quite mediocre. There are many ways you can get a program somewhat up and running, most of which are bad. And even if an LLM smashes two great pieces of code together, there is no guarantee the result will be great.
To create agents that properly replace experienced engineers on code bases with complex logic I think AI models will have to be trained from the ground up to actually learn good engineering principles and figure out all the necessary constraints. And it will not be a matter of simply plowing in more data or increasing context windows.
Mastering any skill is really a matter of identifying key parameters, grasping how they interact and mapping the right constraints through trial, error, and observation. Reinforcing what works, discarding what doesn’t until the most effective methods emerge for each specialized use case. Current models have scale but no (or little?) structure.
I think achieving this with LLMs will be a slow process, and there will be no magical turbo AGI anytime soon. After overuse of AI will inevitably start backfiring it will be specialized idiot savant AI’s with increasingly fine-tuned constraints that will slowly creep past humans in a growing number of disciplines. And will be a very powerful automation tool.
Something like this (where LLM skill level is ratio to max human skill level):
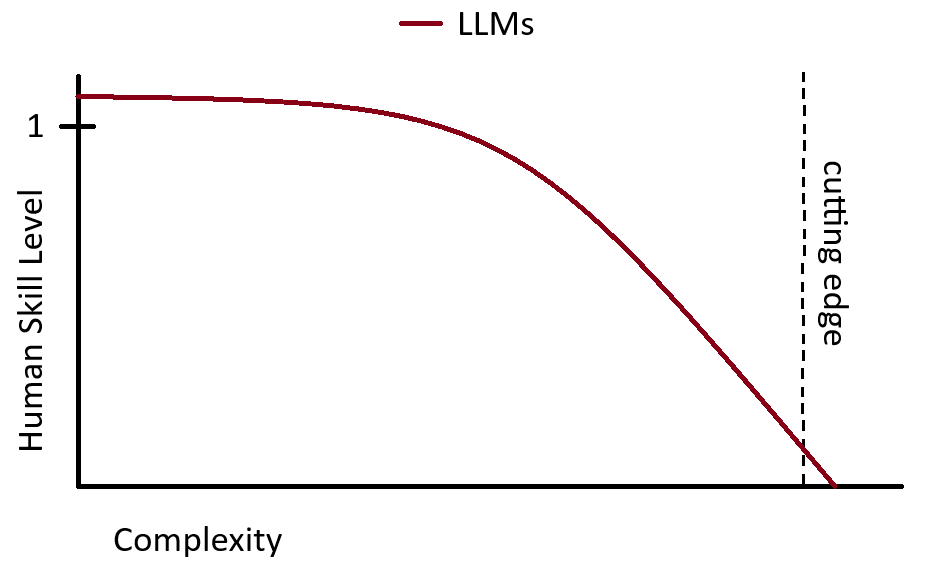
Then after a decade or so it will look something like this:

But it will not really be a true AGI. A true AGI will not need all that human tweaking and will be able to rapidly blast through frontiers with little to no human input. It will be able to learn how to do that autonomously with much more limited training data, and that I think will require major algorithmic breakthroughs and not be a matter of simply increasing size. If that is even possible with current hardware, it would be a bigger deal than the industrial revolution and the internet combined and truly make humans obsolete.
Above graph with AGI would look more like this (pardon my terrible artisinal handmade MS Paint graphs):
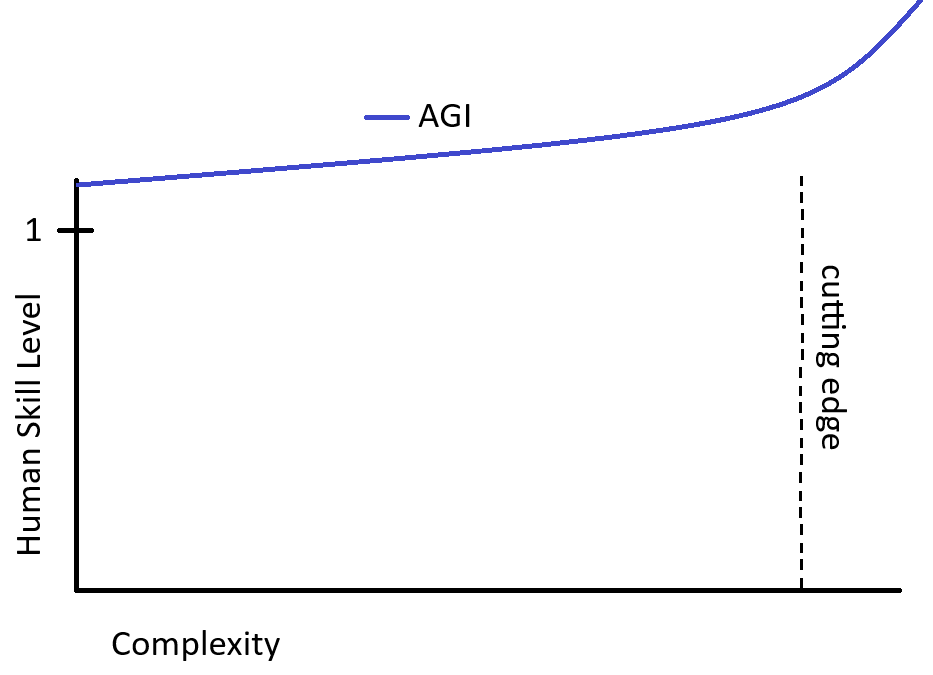
A strong signal that AGI is actually happening is if the ratio of discoveries (either new or back tested) to human generated training data goes up. I think right now this ratio is very small (correct me if I am wrong on this), if it becomes rapidly larger and starts blowing past 1 in a wider range of domains than that is a proper AGI.
If that comes to pass, I will be off to my well-stocked bunker in a secluded location with a good internet connection so I can watch the whole circus from a safe distance.
And those are my thoughts on the future state of AI. It will be interesting to watch in what ways I will be proven right/wrong. More posts coming soon. Will have new stock write-ups, and 2025 stock write-ups so far are performing very well with an average return of over 20%. Wishing everyone who made it this far a fantastic AGI free summer season!

This is timely as I felt myself capitulating into the max hype view in recent weeks. Every tech cycle needs a valley of despair. AI’s will come. It’s simultaneously true that average people are giving way too little respect to what LLMs as they are now mean for the next decade of humanity AND that claims about hockey stick graph improvements in general reasoning, or code that writes itself, or certain observed trends in youth employment having no explanation but AI impact, seem to be widely repeated horseshit. Also great you set invalidation points for your “AGI isn’t close” take in advance.
LLMs cannot function autonomously because they are non-deterministic Nothing can get around this fact. They require human supervision in each scenario they're put to use, either synchronously through prompting and editing the returned completion, or by engineers building comprehensive orchestration workflow on a case by case basis. https://dilemmaworks.substack.com/p/ai-supervised